Today at its I/O conference, Google introduced the Gemini 3.5 family of AI models, along with the innovative Gemini Omni, which can generate videos from any type of input.
The first model released in the Gemini 3.5 series is Gemini 3.5 Flash, now accessible to everyone through the Gemini app and in AI Mode on Google Search. According to Google, this model 'delivers intelligence that rivals large flagship models on multiple dimensions, at the speeds you have come to expect from the Flash series.'
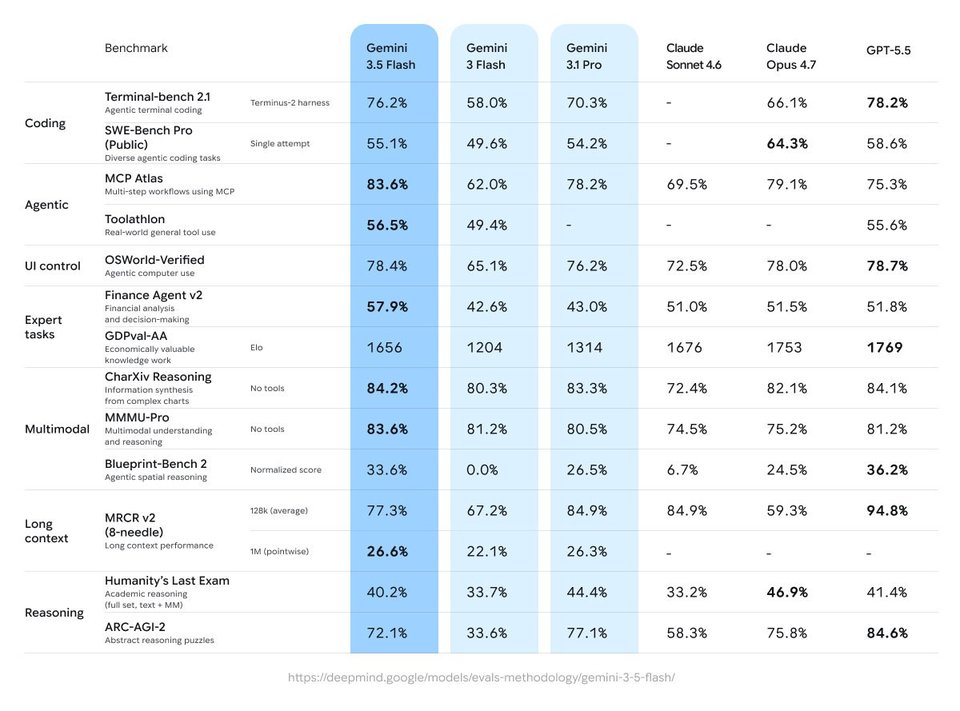
It is the most advanced agentic and coding model yet, surpassing even Gemini 3.1 Pro in challenging coding tasks and agentic assessments while excelling in multimodal comprehension. Gemini 3.5 Flash is now the default model.
Gemini Omni introduces the capability to produce videos from diverse inputs. Users can blend images, audio, video, and text to create high-quality videos 'grounded in Gemini's real-world knowledge.' Once a video is generated, it can be effortlessly edited through conversation.
The initial model in the Gemini Omni series is Gemini Omni Flash, which enables users to alter specific aspects of a video or modify the entire piece while refining the creations across multiple interactions, ensuring continuity with the original scene.
This model boasts 'an improved intuitive understanding of forces like gravity, kinetic energy, and fluid dynamics,' allowing for more realistic scene creation. With Omni, users can utilize their voice and Avatars, providing a digital representation of themselves. Each video features SynthID digital watermarking.
Gemini Omni Flash is available today for all subscribers of Google AI Plus, Pro, and Ultra plans globally through the Gemini app and Google Flow. Additionally, it is being rolled out for free to users on YouTube Shorts and YouTube Create.
Source 1 | Source 2





